
تجزیه و تحلیل دادههای تست کاربردپذیری
تحلیل دادههای تست کاربردپذیری، به شناسایی الگوهای رفتاری کاربران و بهبود طراحی کمک میکند.
فرض کنید معلمی پس از برگزاری امتحان، تنها به تصحیح پاسخها بسنده کند، بیآنکه نگاهی بیندازد و بررسی کند کدام پرسشها برای اغلب دانشآموزان چالشبرانگیز بودهاند یا چه مفاهیمی بهدرستی منتقل نشدهاند. در چنین شرایطی، هرچند آزمون برگزار شده، اما بخش مهمتری از فرایند یادگیری ــ یعنی بازبینی و بهبود ــ نادیده گرفته میشود. در طراحی تجربه کاربری نیز وضعیت مشابهی وجود دارد. زمانی که تست کاربردپذیری انجام میشود و دادههایی از رفتار واقعی کاربران گردآوری میشود، تازه مرحلهای کلیدی آغاز میگردد: تجزیه و تحلیل دادهها. تحلیل دادههای تست کاربردپذیری کمک میکند تا تیم طراحی، رفتار کاربران را دقیقتر بررسی کند و از میان عملکرد آنها، الگوهایی مشخص برای بهبود طراحی بهدست آورد. در این مرحله، تحلیلگران بین آنچه کاربران انجام دادهاند و تصمیماتی که باید در طراحی گرفته شود، ارتباطی حیاتی برقرار میکنند.

انواع دادههای تست کاربردپذیری
در تستهای کاربردپذیری، دادهها به دو دسته اصلی تقسیم میشوند: دادههای کیفی (Qualitative) و دادههای کمی (Quantitative).
-
دادههای کیفی (Qualitative Data)
دادههای کیفی شامل مشاهدات و بازخوردهایی هستند که از گفتار، حرکات، مکثها و انتخابها و رفتارهای تعاملی کاربران بهدست میآیند. این نوع دادهها به ما کمک میکنند تا بفهمیم کاربران دقیقاً در چه بخشهایی دچار سردرگمی یا نارضایتی شدهاند، و چرا یک ویژگی یا مسیر خاص برای آنها چالشبرانگیز بوده است.
-
دادههای کمی (Quantitative)
دادههای کمی شامل اطلاعات عددی و قابل اندازهگیری مانند نرخ موفقیت در انجام یک وظیفه، زمان صرفشده برای انجام هر مرحله، یا تعداد کلیکها و خطاها هستند. این دادهها برای سنجش عملکرد طراحی از نظر دقت و کارایی بسیار مفیدند و امکان مقایسه نسخههای مختلف یا ارزیابی پیشرفتها را فراهم میکنند.
چرا تجزیه و تحلیل دادههای تست کیفی کاربر پیچیده است؟
در ظاهر، تجزیه و تحلیل دادههای تست کاربردپذیری کیفی ساده به نظر میرسد: ثبت مشکلات، بررسی عملکرد کاربران، شمارش خطاها و مرور زمان انجام وظایف. اما وقتی شرایط کمی پیچیدهتر میشود، این روند هم دشوارتر خواهد شد.
برای مثال، اگر در طول یک جلسه، پژوهشگر چند نسخهی مختلف از طراحی را به شرکتکننده نشان دهد، یا سؤالات تحقیق بر درک مفاهیم، کشف قابلیتها یا نحوهی حل مسئله از سوی کاربران تمرکز داشته باشد، تحلیل دادهها بهمراتب چالشبرانگیزتر میشود. همچنین اگر نمونهی اولیهای که تست میکنیم کامل نباشد و همه ویژگیها یا صفحات را نداشته باشد، کار سختتر میشود.
فرض کنید ما یک صفحهی جزئیات محصول طراحی کردهایم و از کاربران خواستهایم محصول مناسب خود را پیدا کنند. حالا میخواهیم بفهمیم:
- آیا بخش مقایسه محصول برای آنها قابل تشخیص بوده؟
- آیا اطلاعات صفحه را درست درک کردهاند؟
- و آیا کاربران توانستهاند مدل ذهنی درستی از نحوهی کار محصول برای خودشان شکل دهند؟
پاسخ به این سؤالات معمولاً از طریق بررسی یک وظیفه ساده بهدست نمیآید. برای تحلیل دقیق، باید:
- رفتار و گفتار کاربران را در بخشهای مختلف جلسه بررسی کنیم.
- شرایط طراحی مطالعه و ویژگیهای شرکتکنندگان را در نظر بگیریم.
- و در نهایت با ترکیب این اطلاعات، به نتیجهای قابل اعتماد برسیم.
تحلیل و تلفیق
تحلیلگران برای رسیدن از دادهها به بینشها و پیشنهادهای کاربردی، از ترکیب دو فعالیت استفاده میکنند: تحلیل و تلفیق. در تحلیل، آنها اطلاعات پیچیده را تجزیه و بررسی میکنند؛ و در تلفیق، این اطلاعات را با یکدیگر ترکیب میکنند تا به برداشتها و بینشهای جدید و معنادار برسند. وقتی دادههای کیفی را تحلیل میکنیم، فرایند تحلیل و تلفیق بهصورت خطی و منظم پیش نمیرود. گاهی لازم است چند بار بین این دو مرحله جابهجا شویم و بازگردیم.
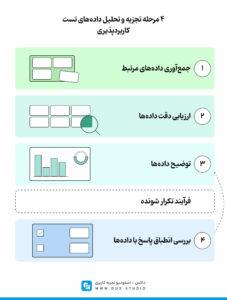
۴ مرحله برای تحلیل دادههای تست کاربردپذیری
تحلیلگران برای دستیابی به بینشهای قابلاعتماد از دادههای تست کاربردپذیری، معمولاً از یک چارچوب چهارمرحلهای استفاده میکنند:
۱. جمعآوری دادههای مرتبط (Collect Relevant Data): انتخاب مشاهدات و نقلقولهایی که مستقیماً به سوالات پژوهش مربوط هستند، و حذف اطلاعات اضافه برای سادهتر شدن تحلیل.
۲. ارزیابی دقت دادهها (Assess For Accuracy): بررسی هر داده از نظر مرتبط و معتبر بودن، تا مطمئن شویم اطلاعات درستی در اختیار داریم.
۳. توضیح دادهها (Explain The Data): ترکیب دادههای انتخابشده، ارزیابیها و دانش تخصصی برای ارائه یک تفسیر یا پاسخ به سوالات پژوهش (مرحله ترکیب و نتیجهگیری).
۴. بررسی انطباق پاسخ با دادهها (Check For Good Fit): اگر همه دادهها با تفسیر ما هماهنگ نباشند، لازم است آن را دوباره بازنویسی کنیم.
نکته مهم این است که مرحلههای سوم و چهارم معمولاً بهصورت رفتوبرگشتی و تکرارشونده انجام میشوند. ابتدا یک فرضیه یا توضیح اولیه شکل میگیرد، اما زمانی که آن را با کل دادهها میسنجیم، ممکن است متوجه نکات جدید یا تناقضهایی شویم که ما را مجبور به اصلاح تفسیرمان میکنند.
-
مرحله اول: دادههای مرتبط (Collect Relevant Data)
تستهای کاربردپذیری معمولاً دادههای زیادی تولید میکنند. در مرحله جمعآوری، شروع به گردآوری تمام دادهها، مشاهدات و نکاتی میکنیم که میتوانند به سوالات پژوهش پاسخ دهند. (این مرحله مانند چیدن سیب از یک باغ تصور کرد؛ به دنبال سیبهایی میگردیم که ظاهر بهتری دارند، چون فکر میکنیم خوشمزهتر هستند.) برای این کار، یادداشتهای جلسه، رونوشتها و در صورت وجود، ویدئوهای ضبطشده را مرور میکنیم. در این حین، مشاهدات و نقلقولهای مرتبط را ثبت یا کدگذاری میکنیم. برای مثال، اگر بخواهیم بررسی کنیم که آیا ویژگی مقایسه در صفحه جزئیات محصول برای کاربران قابل تشخیص است یا نه، ممکن است به یادداشتها و ویدئوها رجوع کنیم تا دادههایی درباره رفتار شرکتکنندگان، صحبتهای آنها در حین جلسه و پاسخهایشان به سؤالات تسهیلگر هنگام انجام تسکهای مرتبط، جمعآوری کنیم. برخی از سوالاتی که ممکن است در این مرحله مطرح شوند عبارتاند از:
-
- آیا شرکتکنندگان از این ویژگی استفاده کردند یا متوجه آن شدند؟ (مثلاً از طریق حرکت نشانگر ماوس روی آن).
- آیا در صحبتهای خود یا در پاسخ به سؤالات تسهیلگر، به ویژگی مقایسه یا نیاز به مقایسه اشارهای داشتند؟
- اگر از این ویژگی استفاده نکردند، تسک مقایسه را به چه شکلی انجام دادند؟
این مرحله، نوعی تحلیل محسوب میشود، چرا که در آن، مجموعه کامل دادهها بدست آمده و بخشهایی از آن که مفیدتر هستند جدا میشوند.

-
مرحله دوم: ارزیابی دقت دادهها (Assess For Accuracy)
در این مرحله، همچنان در مرحله تجزیه و تحلیل دادهها هستیم. حالا وقت آن است که دادههای جمعآوریشده را دقیقتر بررسی کنیم و ببینیم هرکدام چقدر به سوالات پژوهش مرتبط هستند و تا چه حد میتوان به آنها تکیه کرد. همه دادهها ارزش یکسانی ندارند، و ما باید تشخیص دهیم کدام دادهها قابل اعتمادترند.
اگر بخواهیم همان تشبیه چیدن سیب را ادامه دهیم، در این مرحله تحلیلگر هر سیب را یکییکی بررسی میکند تا مطمئن شود لکدار یا خراب نباشد. برای مثال، فرض کنید یکی از شرکتکنندگان گفته که ویژگی مقایسه را دوست دارد، اما در طول تست اصلاً از آن استفاده نکرده است. یا شاید این حرف را در پاسخ به یک سؤال هدایتشدهای که تسهیلگر از او پرسیده بیان کرده باشد (مثلاً پرسیده: «از این قابلیت خوشتون اومد؟»). دانستن این جزئیات کمک میکند تا بهتر تصمیم بگیریم چقدر میتوانیم به آن نظر استناد کنیم.

-
مرحله سوم: توضیح دادهها (Explain The Data)
در این مرحله وارد فاز «تلفیق» میشویم. حالا وقت آن است که مشاهدات، ارزیابیها و دانش تخصصی خودمان را کنار هم قرار دهیم تا به توضیحها یا فرضیههایی منطقی برای دادههایی که جمع کردهایم، برسیم.
تحلیلگران گاهی یک مجموعه داده را به چند شکل مختلف تفسیر میکنند. برای مثال، اگر همه شرکتکنندگان در تست متوجه قابلیت مقایسهای که طراحی کرده بودیم نشده باشند، میتوان چند توضیح احتمالی برای این اتفاق در نظر گرفت:
-
- توضیح ۱: این قابلیت در جایی قرار داشته که انتظار نمیرفت.
- توضیح ۲: آنقدر مشخص یا قابلتشخیص نبوده که توجه کاربر را جلب کند.
- توضیح ۳: این قابلیت برای وظیفهای که کاربر در حال انجامش بوده مفید نبوده، بنابراین اصلاً دلیلی نداشته که دنبال آن بگردد.
تحلیلگران با تکیه بر تجربه در حوزه UX و تا حدی نیز با استفاده از درک انسانی از رفتار کاربر، چنین فرضیههایی را شکل میدهند. برای مثال، اگر پژوهشگر قبلاً روی طراحیهای مشابه کار کرده باشد، احتمالاً تجربهها و مشاهداتی از رفتارهای کاربران در موقعیتهای مشابه در ذهنش دارد که میتواند به او کمک کند.
-
مرحله چهارم: بررسی انطباق پاسخ با دادهها (Check For Good Fit)
برای دقیقتر شدن تفسیرها و افزایش اطمینان نسبت به فرضیههایی که در مرحله پیش شکل گرفتهاند، لازم است آنها را در برابر دادههای موجود ارزیابی کنیم و بسنجیم که تا چه حد با واقعیت مشاهدهشده، برابر هستند. بهعبارت دیگر، باید بررسی شود آیا دادهها از فرضیه حمایت میکنند؟ یا شواهدی وجود دارد که با آن در تضاد باشد و موجب تردید در اعتبار آن شود؟ این مرحله را میتوان به قراردادن قطعهای از پازل در جای درست خود تشبیه کرد.
برای مثال، اگر شرکتکنندگان از قابلیت مقایسه در صفحه معرفی محصول استفاده نکردهاند و ما چنین تفسیر کردهایم که این قابلیت برای آنها ضروری نبوده، در آن صورت انتظار میرود کاربران از راهکار موفق دیگری برای مقایسه استفاده کرده باشند. اما اگر در عمل مشاهده شود که آنها برای مقایسه دچار مشکل شدهاند، چندین تب را بهصورت همزمان باز کردهاند، یا اظهار داشتهاند که مقایسه محصولات دشوار بوده است، این شواهد نشان میدهد که فرضیهی اولیه با دادههای موجود تطابق ندارد و باید رد یا بازنگری شود.
در واقع، این مرحله نوعی تست فرضیه در بستر تحقیقات کیفی است. در اینجا، ما بر اساس فرضیهای که داریم، درباره رفتار کاربر پیشبینیهایی انجام میدهیم؛ و اگر دادهها با این پیشبینیها مطابقت نداشته باشند، خودمان فرضیه را بازبینی یا کنار میگذاریم.
تحقیقات کیفی اغلب میتوانند به بینشهایی ارزشمند و پاسخهایی روشن، منجر شوند؛ اما در کنار آن، گاهی سؤالات تازهای نیز ایجاد میکنند که به بررسیهای بیشتری نیاز دارند. این مسئله کاملاً طبیعی است. تحلیلگری که بتواند دادهها را از زوایای مختلف بررسی کند، فرضیههای گوناگون را با شواهد موجود تطبیق دهد و در نهایت، مجموعهای از تفسیرهای منطقی برای پژوهشهای بعدی ارائه دهد، نشانه تسلط و مهارت بالای او در فرآیند تحلیل است.

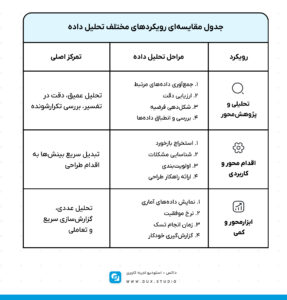
دیگر رویکردهای تحلیل داده در تستهای کاربردپذیری
برای تحلیل دادههای بهدستآمده از تستهای کاربردپذیری، رویکردهای متنوعی وجود دارد. این رویکردها در ظاهر ساختار مشابهی دارند، اما در ترتیب مراحل، میزان تمرکز و نوع خروجی تفاوتهای قابلتوجهی با یکدیگر دارند.
برخی تحلیلگران از یک رویکرد تحلیلی و پژوهشمحور استفاده میکنند که با انتخاب دقیق دادههای مرتبط با پرسش تحقیق آغاز میشود. در این شیوه، دادهها با ارزیابیهای عمیق و تجربهی تیم ترکیب میشوند تا فرضیههایی قابل بررسی شکل بگیرد. سپس، این فرضیهها در برابر دادههای واقعی سنجیده میشوند تا اعتبار آنها بررسی شود. این رویکرد برای پروژههایی مناسب است که به تحلیل دقیق، تدریجی و قابل بازنگری نیاز دارند.
در مقابل، گروهی دیگر ترجیح میدهند از رویکرد کاربردی و اقداممحور استفاده کنند. در این روش، تمرکز بر شناسایی سریع مشکلات، خلاصهسازی دادهها و تبدیل آنها به راهکارهای طراحی مشخص است. چنین رویکردی معمولاً در پروژههایی با محدودیت زمانی یا نیاز به تصمیمگیری سریع بهکار گرفته میشود.
نوع سومی از رویکرد نیز وجود دارد که بهشکل ابزارمحور و کمی انجام میشود. در این حالت، تحلیلگر با کمک دادههای عددی مانند نرخ موفقیت، زمان انجام تسک یا میزان خطا، تصمیمگیریهای خود را انجام میدهد. این مدل بیشتر در تستهایی با مقیاس بالا، یا زمانی که از ابزارهای تحلیلی خودکار استفاده میشود، کاربرد دارد.
در مجموع، انتخاب بهترین روش تحلیل دادههای تست کاربردپذیری به عواملی مانند هدف تحقیق، نوع پروژه، تجربه تیم و منابع در دسترس بستگی دارد. در این مقاله، ما از رویکرد تحلیلی مرحلهبهمرحله استفاده کردهایم، چرا که دقت بالا و ساختار منسجم آن، بستری مناسب برای دستیابی به بینشهای قابلاعتماد در طراحی تجربه کاربری فراهم میکند.
نتیجهگیری
تجزیه و تحلیل دادههای تست کاربردپذیری، مرحلهای کلیدی در فرایند طراحی تجربه کاربری است که امکان تبدیل مشاهدات خام به بینشهای دقیق و قابلاقدام را فراهم میسازد.
در این مقاله، به مراحل اصلی تحلیل شامل انتخاب دادههای مرتبط، ارزیابی دقت آنها، شکلدهی فرضیهها و سنجش آنها در برابر دادههای واقعی، پرداختیم. همچنین تفاوت رویکردهای مختلف در تحلیل، از مدلهای ساختارمند تا روشهای ابزارمحور، مورد بررسی قرار گرفت. مشخص شد که هر رویکرد بسته به هدف، نوع پروژه و ترکیب تیم، مسیر متفاوتی را از داده تا تصمیم طراحی طی میکند.
در مجموع، تحلیل مؤثر دادههای تست کاربردپذیری زمانی ارزشمند خواهد بود که با نگاه چندجانبه، آزمون فرضیهها و درک درست از زمینه و کاربران همراه شود. این رویکرد میتواند راهگشای تصمیمهای طراحی آگاهانه و تجربهای بهینه برای کاربر باشد.
شما در پروژههای خود چگونه دادههای تست کاربردپذیری را تحلیل میکنید؟ آیا روشی خاص یا مرحلهای وجود دارد که برای شما نتیجهبخشتر بوده باشد؟ تجربهتان را با ما در میان بگذارید.





دیدگاه کاربران